Objetivo
Apresentar conceitos básicos sobre Hard State e Soft State.
Público-alvo
Administradores e usuários da Solução OpMon.
Estados
Existem dois tipos de estados cruciais na lógica de monitoração. Esses estados determinam quando um elemento monitorado irá alarmar e as notificações serão enviadas.
Além de evitar falsos alarmes de problemas transitórios, o OpMon permite definir quantas vezes um elemento deve ser verificado antes de ser considerado um problema “real”.
Sempre que um elemento estiver no estado OK, ele estará em Hard State (OK) também.
Informações básicas de checagem:
Como funciona:
Quando um host ou serviço está em estado “OK” ele está em “Hard State”, porém quando o mesmo, ao ser checado, obtiver algum resultado que caracterize indisponibilidade, alto uso de recurso ou qualquer anomalia, o estado é alterado para “Soft State”, onde será feita N checagens conforme definido nas configurações (Maximum Check Attempts), e cada checagem será feita em N minutos conforme foi configurado (Retry Check Interval).
Após atingir o máximo de tentativas de checagem o estado será alterado para “Hard State”.
Caso o host ou serviço volte para o estado “OK”, durante essas tentativas, o mesmo assumirá imediatamento o estado de OK – Hard State.
Caso ele permaneça no estado não OK, ele assumirá os estados de Critical, Warning, Fora, Desconhecido, etc – Hard State, e irá gerar um incidente e notificar os contatos que foram vinculados ao host ou serviço.
Exemplos:

Considere a imagem abaixo.
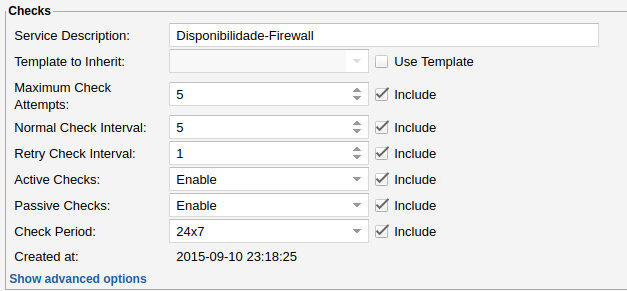
Suponha que o serviço Firewall esteja “OK”. A cada 5 minutos será feita uma checagem normal. Porém se este serviço parar por algum motivo, quando ocorrer a checagem normal este serviço será alterado automaticamente para “Soft State” e uma anotação de tentativas e tentativas máximas irá aparecer na tela principal do OpMon.
A partir disso, OpMon irá realizar uma checagem a cada 1 minutos até o máximo de 5 re-checagens.

Caso alguma dessas re-checagens colete o valor de OK para este serviço, o mesmo mudará de “Soft State” para “OK – Hard State”.
Caso o serviço não volte a funcionar corretamente ele será alterado de “Soft State” para “Hard State”, assumindo o estado Critical, Warning ou Desconhecido.
Será gerado um alerta, notificando assim o contato vinculado ao serviço em questão em apenas 5 minutos.