Objetivo
Demonstrar como configurar um ambiente com dois servidores OpMon em cluster.
Esta documentação é destinada ao OpMon à partir da versão 10, rodando em Red Hat 8.x
Suporte
Essa configuração é suportada pela OpServices para os clientes OpMon Premium e pelos parceiros para os clientes OpMon PRO.
Público-Alvo
Administradores do OpMon.
Pré-Requisitos
- É preciso ter dois IPs fixos na lan, um para cada nodo do cluster.
- É preciso ter dois IPs virtuais, um para cada nodo do cluster, para que possa se fazer balanceamento por Round Robin.
- É preciso que todos os IPs mencionados façam parte da mesma LAN, assim garantindo a comunicação entre os nodos.
- Os dois servidores devem estar na mesma arquitetura (x86_64).
- Os dois servidores devem estar na mesma versão do OpMon.
- É preciso criar a devida licença, que suporte todos os IPs de ambos nodos, assim terá uma licença para o cluster, ao invés de uma para cada servidor.
- É necessário realizar a configuração de NTP para a sincronização de horário de ambos servidores, ou com um servidor interno ou externo, caso tenha dúvida de como realizar o procedimento, pode seguir o procedimento descrito aqui.
- As portas abaixo devem estar liberada para funcionamento do OpMon em cluster:
- tcp/udp – 80
- tcp/udp – 443
- tcp/udp – 5666
- tcp/udp – 54978
- tcp/udp – 3306
- tcp/udp – 694
Premissa importante
- Entende-se por IP_NODO_MASTER e IP_NODO_SLAVE os IPs que foram configurados nas interfaces eth0 de ambos os nodos.
Configurando um novo cluster
1) Renomear os hosts adequadamente
Para que o cluster funcione corretamente, cada host deve ter um nome diferente. Em outras palavras, quando se rodar o comando ‘uname -n‘ os nomes retornados nos nodos devem ser únicos (diferentes um do outro). Para alterar o hostname dos nodos, basta editar o arquivo /etc/sysconfig/network e definir a opção HOSTNAME corretamente.
Veja o exemplo abaixo, trocaremos o hostname de opmon para NODO01
[root@opmon ~]# uname -n opmon [root@opmon ~]# vim /etc/sysconfig/network
Edite o arquivo para um novo nome:
[root@opmon ~]# cat /etc/sysconfig/network NETWORKING=yes NETWORKING_IPV6=yes HOSTNAME=NODO01 [root@opmon ~]# hostname opmon-nodo01 [root@opmon ~]# uname -n NODO02
Repita o processo agora para o NODO02.
Os novos nomes devem ser anotados pois precisaremos deles mais adiante, quando formos configurar os nodos do cluster.
Importante: O comando hostname troca o nome para a sessão atual, enquanto a edição do arquivo /etc/sysconfig/network faz a mudança persistente.
2) Assegurar a interconectividade entre os nodos:
Configuradas as interfaces eth0 de ambos os nodos, testar a interconectividade entre os nodos usando para tal o comando ping. O acesso pela interface eth0 deve estar funcional, antes de se prosseguir com este tutorial. Para a configuração de rede em ambos os nodos utilizar o utilitário do redhat chamado system-config-network.
3) Atualizar o OpMon
O OpMon deve estar na última versão antes da implementação do cluster, para realizar o procedimento siga os passos descritos aqui. Em caso de problemas neste passo o processo deve ser abortado e um contato com a OpServices deve ser feito.
4) Configurando o MariaDB
O servidor MariaDB nesta configuração de cluster será configurado como multi-master. Os dois nodos se comportarão como master e slave ao mesmo tempo. Para tal, precisa-se primeiro configurar a opção de ‘log-bin’, para a geração dos incrementais. Para tal, siga os passos abaixo.
Pare o MariaDB no NODO01:
[root@NODO01 ~]# service mysql stop
Editar o arquivo /etc/my.cnf.d/opmon.cnf e descomentar as 3 linhas abaixo:
log-bin =incremental log-bin-index =inc-index sync_binlog =0
Iniciar novamente o MariaDB:
[root@NODO01 ~]# service mysql start
Configurar a senha de acesso ao MariaDB com o seguinte comando:
[root@NODO01 ~]# mysqladmin -u root password 'oppass'
Logue no MariaDB para autorizar o acesso ao usuário “root@127.0.0.1”.
[root@NODO01 ~]# mysql -p -A -u root MariaDB [(none)]> GRANT ALL ON *.* TO root@'127.0.0.1' IDENTIFIED BY 'oppass'; Query OK, 0 rows affected (0.00 sec) MariaDB [(none)]> flush privileges; Query OK, 0 rows affected (0.00 sec)
Ajustar o OpMon para que consiga acessar o banco de dados com a senha configurada no último passo. Para tanto, editar o arquivo abaixo e substituir a variável demostrada:
[root@NODO01 ~]# vim /usr/local/opmon/etc/db.php
$DBPASS="oppass";
Logue no MariaDB para autorizar o acesso remoto a partir do NODO02. Em outras palavras, estamos permitindo que conexões ao MariaDB do NODO01 sejam feitas a partir do NODO02:
[root@NODO01 ~]# mysql -p -A -u root MariaDB [(none)]> GRANT ALL ON *.* TO root@'IP_ETH0_NODO02' IDENTIFIED BY 'oppass'; Query OK, 0 rows affected (0.00 sec) MariaDB [(none)]> flush privileges; Query OK, 0 rows affected (0.00 sec)
Repita o mesmo processo para o Nodo02.
ATENÇÃO: Substituir no passo acima, os nomes IP_ETH0_NODO01 e IP_ETH0_NODO02 pelos respectivos endereços IPs dos dois nodos. Todo procedimento descrito acima deve ser feitos nos dois nodos do cluster, alterando os IPs corretamente.
Exportar a configuração no Nodo01 com o seguinte comando:
[root@NODO01 ~]# /usr/local/opmon/utils/opmon-export.php
Aguardar o processo de export terminar.
Após a execução dos mesmos passos no NODO02, podemos prosseguir. Precisamos agora testar se conseguimos conectar do NODO01 para o NODO02 e vice versa. A partir do NODO01, rodar o seguinte comando:
[root@NODO01 ~]# mysql -u root --password=oppass -h IP_ETH0_NODO02 -e exit && echo OK OK
Apenas um OK deve aparecer na tela. Repetir o mesmo comando, agora a partir do NODO02:
[root@NODO02 ~]# mysql -u root --password=oppass -h IP_ETH0_NODO01 -e exit && echo OK OK
Voltamos agora ao NODO01 para efetuarmos um dump da base de dados, com o seguinte comando:
[root@NODO01 ~]# /usr/local/opmon/utils/opmon-base.pl -E Logging on file /var/log/opdb-dump.log 2014/10/2 9:28:46 - Starting all databases export 2014/10/2 9:28:46 - -> Dumping all databases
Verifique se houve algum erro durante o dump, olhando o conteúdo no arquivo /var/log/opdb-dump.log. Em caso de erro, abortar o processo e entrar em contato com a OpServices.
Copiar o dump da base de dados do NODO01 para o NODO02 no mesmo lugar:
[root@NODO01 ~]# scp -r /var/tmp/opmondb root@IP_ETH0_NODO02:/var/tmp/
Acesse o NODO02 e restaurar o dump copiado (para 50GB de dump demora em torno de 6hs, para 86GB em torno de 9hs):
[root@NODO02 ~]# /usr/local/opmon/utils/opmon-base.pl -R
Aguardar o processo de restauração terminar e verificar no arquivo /var/log/opdb-dump.log por possíveis erros. Voltamos então ao NODO01 para então configurarmos a replicação do MariaDB.
5) Ajuste de memória
Ajuste o parãmetro tokudb_cache_size, que é a memória reservada para o banco no /etc/my.cnf.d/opmon.cnf de acordo com cada cliente, por exemplo:
a) Cliente com OpMon e banco no mesmo servidor, usa-se 1/8 da memória, assim temos.
| Total RAM Servidor | Total RAM Banco |
| 4GB | 512M |
| 8GB | 1G |
| 16GB | 2G |
| 32GB | 4G |
| 64GB | 8G |
b) Cliente com banco dedicado, usa-se até 80% da memória, assim temos.
| Total RAM Servidor | Total RAM Banco |
| 4GB | 3G |
| 8GB | 6G |
| 16GB | 13G |
| 32GB | 26G |
| 64GB | 51G |
c) Deve-se ajustar o parâmetro tokudb_cache_size de acordo com as regras acima e manter a innodb_buffer_pool_size em 256M. Ficando da seguinte maneira:
# tokudb settings tokudb_row_format = 'tokudb_snappy' tokudb_commit_sync = 0 tokudb_loader_memory_size = 100M tokudb_cache_size = 1G tokudb_tmp_dir = /var/tmp tokudb_fs_reserve_percent = 0 tokudb_directio = 0 tokudb_prelock_empty = 0 tokudb_support_xa = 0 tokudb_dir_per_db = 1 # innodb settings innodb_buffer_pool_size = 256M innodb_log_file_size = 512M innodb_log_buffer_size = 16M innodb_flush_log_at_trx_commit = 0 innodb_lock_wait_timeout = 50 innodb_file_per_table = 1 innodb_support_xa = 0 innodb_log_files_in_group = 2 innodb_thread_concurrency = 8
O procedimento mencionado acima deve ser executado nos dois nodos do OpMon.
No NODO01 edite novamente o arquivo /etc/my.cnf.d/opmon.cnf e descomente as seguintes linhas:
server-id =1 auto_increment_increment =10 auto_increment_offset =1 slave-skip-errors =all
Atenção: As linhas acima são precedidas por uma linha que diz Configuration side A.
No NODO_02 agora, edite o arquivo /etc/my.cnf.d/opmon.cnf também e descomente as seguintes linhas:
server-id =2 auto_increment_increment =10 auto_increment_offset =2 slave-skip-errors =all
Ao contrário da configuração do NODO01, as linhas acima são precedidas por uma linha que diz Configuration side B. Observe que o server-id e o auto_increment_offset são diferentes do NODO01.
Reinicie o MariaDB em cada um dos nodos, primeiro no NODO01 e depois no NODO02
[root@NODO01 ~]# service mysql restart Shutting down MySQL.. SUCCESS! Starting MySQL. SUCCESS!
[root@NODO02 ~]# service mysql restart Shutting down MySQL.. SUCCESS! Starting MySQL. SUCCESS!
Apos isso entrar no MariaDB em cada nodo:
[root@NODO01 ~]# mysql -u root -p
No NODO1, rodar a seguinte query, trocando IP_ETH0_NODO02 pelo IP da eth0 do NODO02:
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='IP_ETH0_NODO02',
-> MASTER_USER='root',
-> MASTER_PASSWORD='oppass',
-> MASTER_LOG_FILE='incremental.000001',
-> MASTER_LOG_POS=0;
Query OK, 0 rows affected (0.03 sec)
MariaDB [(none)]> start slave;
Query OK, 0 rows affected (0.00 sec)
No NODO2, rodar a seguinte query, trocando IP_ETH0_NODO01 pelo IP da eth0 do NODO01:
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='IP_ETH0_NODO01',
-> MASTER_USER='root',
-> MASTER_PASSWORD='oppass',
-> MASTER_LOG_FILE='incremental.000001',
-> MASTER_LOG_POS=0;
Query OK, 0 rows affected (0.03 sec)
MariaDB [(none)]> start slave;
Query OK, 0 rows affected (0.00 sec)
Agora precisamos validar se a configuração de multi-master do MariaDB está efetivamente funcionando, para tal logue no MariaDB do NODO01 e rode o comando conforme abaixo:
[root@NODO01 ~]# mysql -u root -p
Enter password:
...
MariaDB [(none)]> show slave statusG
*************************** 1. row ***************************
Slave_IO_State:
Master_Host: 192.168.2.2
Master_User: root
Master_Port: 3306
Connect_Retry: 60
Master_Log_File:
Read_Master_Log_Pos: 4
Relay_Log_File: mysqld-relay-bin.000001
Relay_Log_Pos: 98
Relay_Master_Log_File:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 0
Relay_Log_Space: 98
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
1 row in set (0.00 sec)
Devemos observar as seguintes linhas:
... Slave_IO_Running: Yes Slave_SQL_Running: Yes ...
Ambas devem estar em Yes. Caso elas não estejam em Yes, aguardar um minuto e tentar o comando novamente. Se elas não ficarem em Yes, significa um problema. Abortar o processo e contatar a OpServices. Repetir o mesmo processo, agora no NODO02:
[root@NODO02 ~]# mysql -u root -p
Enter password:
...
MariaDB [(none)]> show slave status/G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.2.1
Master_User: root
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: incremental.000003
Read_Master_Log_Pos: 172320
Relay_Log_File: mysqld-relay-bin.000005
Relay_Log_Pos: 172459
Relay_Master_Log_File: incremental.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 172320
Relay_Log_Space: 172459
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
1 row in set (0.00 sec)
mysql> exit
Ficando Yes em ambas as opções acima nos dois nodos, o próximo passo é testar a sincronismo de base. As operações abaixo podem atrasar um pouco para acontecer, pois as bases podem estar sincronizando, mas como testamos a configuração com o comando “show slave statusG” o sincronismo deverá acontecer.
No NODO01 acessar o mariadb e rodar o seguinte comando:
[root@NODO01 ~]# mysql -u root -p Enter password: ... MariaDB [(none)]> create database testesincronismo; Query OK, 1 row affected (0.00 sec) MariaDB [(none)]> exit
Agora, no NODO02, verificar se a base de dados criada acima (testesincronismo) existe:
[root@NODO02 ~]# mysql -u root -p Enter password: ... MariaDB [(none)]> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | Syslog | | mysql | | nedi | | opcfg | | opmon4 | | opperf | | seagull | | snmptt | | test | | testesincronismo | +--------------------+ 11 rows in set (0.00 sec)
Se a base de dados não existir, aguarde um tempo pois o sincronismo pode estar um pouco atrasado. Caso ele não apareça em alguns minutos, abortar o processo. Em caso afirmativo, temos a certeza de que a sincronização do NODO01 para o NODO02 está funcionando corretamente, precisamos agora testar o inverso, ou seja, o sincronismo do NODO02 para o NODO01. Para tanto, basta removermos a base de dados testesincronismo no mysql do NODO02 e ela deverá sumir também no NODO01 conforme abaixo:
No NODO02:
[root@NODO02 ~]# mysql -u root -p Enter password: ... MariaDB [(none)]> drop database testesincronismo; Query OK, 0 rows affected (0.00 sec)
E no NODO01, a base deverá ter sumido:
[root@NODO01 ~]# mysql -u root -p Enter password: ... MariaDB [(none)]> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | Syslog | | mysql | | nedi | | opcfg | | opmon4 | | opperf | | seagull | | snmptt | | test | +--------------------+ 10 rows in set (0.00 sec) MariaDB [(none)]>
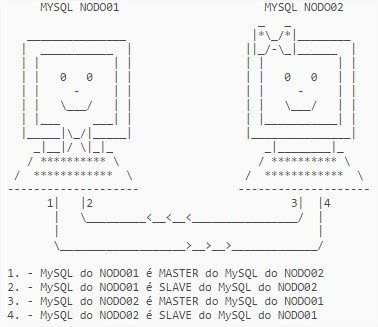
Com isso, encerramos a configuração do MySQL dos dois nodos do cluster. A configuração fica como especificado abaixo (a imagem abaixo é a mesma do procedimento do MySQL, mas a ideia permanece):
6) Configurando o SSH sem senha
Para que haja um sincronismo de arquivos físicos entre os nodos, se faz necessário permitir o login via SSH de um nodo para o outro sem a necessidade de senha. Para tal, teremos que gerar as chaves criptográficas em ambos os nodos. No NODO01 executar:
[root@NODO01 ~]# ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: 43:43:fa:d6:3a:41:91:f9:22:5f:63:b2:36:b2:d8:7d root@homolog-nodo01 [root@NODO01 ~]#
Apenas pressione ENTER em todas as perguntas feitas. Agora que a chave foi criada no NODO01, precisamos copiar a parte pública dela para o NODO02. Para isso, rodamos o seguinte comando:
[root@NODO01 ~]# ssh-copy-id <IP_ETH0_NODO02> Now try logging into the machine, with "ssh '192.168.10.126'", and check in: .ssh/authorized_keys to make sure we haven't added extra keys that you weren't expecting. [root@NODO01 ~]#
Agora precisamos testar o acesso do NODO01 ao NODO02 via SSH e a senha não deverá ser perguntada. Para tanto, basta a partir do NODO01 acessar via SSH o NODO02. Feito o teste e validando o acesso ssh sem senha, devemos repetir o processo todo no NODO02, ou seja, geramos a chave, copiamos a parte publica para o NODO1 e testamos novamente o acesso ssh.
7) Configurando o sincronismo de arquivos
Primeiro precisamos validar se o utilitário rsync se encontra instalado em ambas as máquinas. Para isso, mandamos instala-lo via yum:
[root@NODO01 ~]# yum install rsync -y
[root@NODO02 ~]# yum install rsync -y
Agora, no NODO01, precisamos editar o arquivo /etc/syncfiles.conf e configurar os IPs conforme abaixo:
[root@NODO01 ~]# vim /etc/syncfiles.conf
Devemos deixar os seguintes parâmetros com a seguinte configuração:
PORT=22 SLEEPTIME=60 HOST=IP_ETH0_NODO02
Agora a configuração inversa deve ser feita no NODO02, ou seja:
[root@NODO02 ~]# vim /etc/syncfiles.conf
Devemos deixar os seguintes parâmetros com a seguinte configuração:
PORT=22 SLEEPTIME=60 HOST=IP_ETH0_NODO01
Voltamos agora nossa atencão novamente ao NODO01. No diretório /etc/syncfiles.d devem conter os seguintes arquivos, conforme abaixo:
etc.conf libexec.conf syncfilesd.conf var.conf license.conf
Muitas vezes, por padrão o arquivo license.conf não vem criado. Caso ocorra isso, crie o arquivo license.conf dentro do diretório /etc/syncfiles.d com o seguinte conteúdo:
dir=/usr/local/opmon/lic to=/usr/local/opmon/
Salve e saia do arquivo.
Pronto, temos agora a configuração do sincronismo dos arquivos configurada. Precisamos apenas testá-la. Para tanto rodamos o comando a seguir no NODO01:
[root@nodo01 ~]# service syncfiles start Starting cluster's syncronization script [root@nodo01 ~]#
Verificamos o arquivo /var/log/syncfiles.log procurando por possíveis erros de sincronismo. Caso tudo esteja OK, devemos parar o processo de sincronismo e deixá-lo parado por enquanto:
[root@nodo01 ~]# service syncfiles stop Stopping cluster's syncronization script [root@nodo01 ~]#
8) Configurando o Cluster e seus Recursos
O pacemaker e o CMAN são os utilitários que mantém o OpMon funcionando, mesmo com a queda de um dos nodos. Precisamos agora configurá-los. Primeiramente precisamos tirar o processo do OpMon e do syncfiles do boot das máquinas, pois quem vai gerenciar se estes devem subir ou não será o Pacemaker a partir de agora. Para tanto, nos dois nodos, rodar os seguintes comandos:
[root@nodo01 ~]# systemctl disable syncfiles [root@nodo01 ~]# systemctl disable opmon [root@nodo01 ~]# systemctl disable gearmand [root@nodo01 ~]# systemctl stop syncfiles [root@nodo01 ~]# systemctl stop opmon [root@nodo01 ~]# systemctl stop gearmand
[root@nodo02 ~]# systemctl disable syncfiles [root@nodo02 ~]# systemctl disable opmon [root@nodo02 ~]# systemctl disable gearmand [root@nodo02 ~]# systemctl stop syncfiles [root@nodo02 ~]# systemctl stop opmon [root@nodo02 ~]# systemctl stop gearmand
Vamos agora instalar os pacotes para que o cluster funcione corretamente. Nos dois nodos precisamos rodar o seguinte comandos:
Habilitar o repositório HA do Red Hat:
[root@NODO01 ~]# subscription-manager repos --enable=rhel-8-for-x86_64-highavailability-rpms
[root@NODO02 ~]# subscription-manager repos --enable=rhel-8-for-x86_64-highavailability-rpms
Instalar os pacotes:
[root@NODO01 ~]# dnf install pacemaker corosync pcs
[root@NODO02 ~]# dnf install pacemaker corosync pcs
Agora precisamos nos certificar de que todos os nodos estão listados em /etc/hosts. Para isso, basta editar o arquivo citado acima e inserir as entradas como as que seguem, ajustando obviamente o IP para o correspondente:
<IP_ETH0_NODO01> NODO01 <IP_ETH0_NODO02> NODO02
Repita o processo no NODO02.
Agora precisamos iniciar os serviços do cluster e adicionar os dois nodos no mesmo:
[root@NODO01 ~]# service pcsd start
[root@NODO02 ~]# service pcsd start
ATENÇÃO: Algumas partes do procedimento a seguir devem ser executadas em apenas um host, portanto atente para as caixas de diálogo, pois estas informa em qual NODO a operação está sendo executada.
Definir uma senha para o usuário hacluster, criado durante a instalação dos pacotes.
Este usuário é quem faz a conexão autenticada dos serviços do cluster em ambos os nodos, no exemplo abaixo, definimos a senha ‘oppass’.
[root@NODO01 ~]# passwd hacluster
[root@NODO02 ~]# passwd hacluster
Adição e configuração dos nodos ao cluster:
[root@NODO01 ~]# pcs host auth NODO01 NODO02
[root@NODO01 ~]# pcs cluster setup opmon NODO01 NODO02
O comando acima cria um cluster chamado ‘opmon’ e adiciona ao mesmo os dois nodos previamente configurados
[root@NODO01 ~]# pcs cluster start --all
[root@NODO01 ~]# systemctl enable pacemaker
[root@NODO01 ~]# systemctl enable corosync
[root@NODO01 ~]# systemctl enable pcsd
Para monitorar a saúde do cluster, os status dos nodos até aqui, pode ser utilizado um dos comandos abaixo:
[root@NODO01 ~]# pcs status
[root@NODO01 ~]# pcs cluster status
[root@NODO01 ~]# crm_mon
Instalando o CRMSH para gerenciamento dos recursos do cluster:
[root@NODO01 ~]# cd /tmp [root@NODO01 ~]# wget http://repo.opservices.com.br/rpms/plugins/crmsh.4.3.1.tar.gz [root@NODO01 ~]# tar -xvzf crmsh.4.3.1.tar.gz [root@NODO01 ~]# cd crmsh-4.3.1/ [root@NODO01 ~]# dnf install autoconf automake [root@NODO01 ~]# ./autogen.sh [root@NODO01 ~]# ./configure [root@NODO01 ~]# make [root@NODO01 ~]# make install
A partir de agora, pode ser utilizado a interface cli crmsh para declaração dos recursos do cluster.
DICA: Para exibir as configurações do cluster até aqui, rode o comando crm configure show
No NODO01 agora, definimos a configuração padrão do Pacemaker, utilizando o comando: crm configure, conforme o prompt abaixo:
Observação: Nos recursos abaixo, está declarado também o Postfix para ser gerenciado pelo cluster ao ocorrer algum failover, portanto o sistema deve estar com o serviço
Postfix instalado corretamente.
[root@NODO01 ~]# crm configure crm(live)configure# property start-failure-is-fatal=false crm(live)configure# property stonith-enabled=false crm(live)configure# property no-quorum-policy=ignore crm(live)configure# rsc_defaults rsc_defaults-options: migration-threshold=0 failure-timeout=2s resource-stickiness=50
Adicionamos agora os IPs virtuais que usaremos para acesso web (round-robin), com os seguintes comandos:
crm(live)configure# primitive Virtual_Ip_Nodo01 ocf:heartbeat:IPaddr2 params ip=<IP_VIRTUAL_NODO01> cidr_netmask=32 op monitor interval=30s crm(live)configure# primitive Virtual_Ip_Nodo02 ocf:heartbeat:IPaddr2 params ip=<IP_VIRTUAL_NODO02> cidr_netmask=32 op monitor interval=30s
Lembre-se de substituir as variáveis corretamente com os IPs virtuais que serão usados no round-robin.
Passamos agora a definir os processos e serviços que serão controlados pelo cluster:
crm(live)configure# primitive opmon-pri systemd:opmon op monitor interval="10" timeout="30" op start interval="0" timeout="120" op stop interval="0" timeout="240" crm(live)configure# primitive syncfiles-pri systemd:syncfiles op monitor interval="10" timeout="30" op start interval="0" timeout="120" op stop interval="0" timeout="120" crm(live)configure# primitive opdiscovery-pri systemd:opdiscovery op monitor interval="10" timeout="30" op start interval="0" timeout="120" op stop interval="0" timeout="120" crm(live)configure# primitive gearmand-pri systemd:gearmand op monitor interval="10" timeout="30" op start interval="0" timeout="120" op stop interval="0" timeout="120" crm(live)configure# primitive gearman-utils-pri systemd:gearman-utils op monitor interval="10" timeout="30" op start interval="0" timeout="120" op stop interval="0" timeout="120" crm(live)configure# primitive memcached-pri systemd:memcached op monitor interval="10" timeout="30" op start interval="0" timeout="120" op stop interval="0" timeout="120" crm(live)configure# primitive postfix-pri systemd:postfix op monitor interval="10" timeout="30" op start interval="0" timeout="120" op stop interval="0" timeout="120" crm(live)configure# primitive opmonconnector-pri systemd:opmonconnector op monitor interval="10" timeout="30" op start interval="0" timeout="120" op stop interval="0" timeout="120"
Agora precisamos definir um grupo de primitivas, pois os mesmos devem rodar em apenas um servidor:
crm(live)configure# group OpmonProcesses syncfiles-pri opmon-pri crm(live)configure# group OpmonExtraProcesses gearmand-pri opmonconnector-pri gearman-utils-pri memcached-pri opdiscovery-pri postfix-pri
Feita a adição dos IPs virtuais, agora precisamos definir o local dos IP Virtuais subirão, lembrando que NODO01 e NODO02 devem ser substituídos pelos hostnames dos nodos em questão:
crm(live)configure# location Loc_vip_nodo01 Virtual_Ip_Nodo01 100: NODO01 crm(live)configure# location Loc_vip_nodo02 Virtual_Ip_Nodo02 100: NODO02 crm(live)configure# location Loc_OpmonProcesses OpmonProcesses inf: NODO01
Por último, devemos devemos realizar uma clonagem de grupos:
crm(live)configure# clone OpmonExtraProcesses_Clone OpmonExtraProcesses
Saindo e salvando as configurações, execute o seguinte comando:
crm(live)configure# commit crm(live)configure# end There are changes pending. Do you want to commit them (y/n)? y crm(live)# quit bye
Podemos ter algum problema no commit das informações. Também podemos adotar outra tática, ou seja, irmos adicionandos os recursos (IPs virtuais, processos, grupos) e ir sempre saindo e fazendo commit das informações.
Para visualizarmos todas as configurações feitas até o momento, devemos usar o comando crm configure show conforme exemplo abaixo:
[root@NODO01 ~]# crm configure show node NODO01 attributes standby=off node NODO02 primitive gearman-utils-pri systemd:gearman-utils op monitor interval=10 timeout=30 op start interval=0 timeout=120 op stop interval=0 timeout=120 primitive gearmand systemd:gearmand op monitor interval=10 timeout=30 op start interval=0 timeout=120 op stop interval=0 timeout=120 primitive memcached-pri systemd:memcached op monitor interval=0 int primitive opdiscovery-pri systemd:opdiscovery op monitor interval=10 timeout=30 op start interval=0 timeout=120 op stop interval=0 timeout=120 primitive opmon systemd:opmon op monitor interval=10 timeout=30 op start interval=0 timeout=120 op stop interval=0 timeout=240 primitive opmonconnector-pri systemd:opmonconnector op monitor interval=10 timeout=30 op start interval=0 timeout=120 op stop interval=0 timeout=120 primitive postfix-pri lsb:postfix op monitor interval=10 timeout=30 op start interval=0 timeout=120 op stop interval=0 timeout=120 primitive syncfiles lsb:syncfiles op monitor interval=10 timeout=30 op start interval=0 timeout=120 op stop interval=0 timeout=120 meta target-role=Started primitive vip_nodo01 IPaddr2 params ip=<IP_VIRTUAL_NODO01> cidr_netmask=32 op monitor interval=30s meta target-role=Started primitive vip_nodo02 IPaddr2 params ip=<IP_VIRTUAL_NODO02> cidr_netmask=32 op =30s group OpmonExtraProcesses opdiscovery-pri gearman-utils-pri memcached-pri postfix-pri gearmand opmonconnector-pri group opmonprocesses syncfiles opmon meta target-role=Started clone OpmonExtraProcesses_Clone OpmonExtraProcesses location cli-ban-vip_nodo02-on-NODO02 vip_nodo02 role=Started -inf: NODO02 location loc_opmonprocesses opmonprocesses inf: NODO01 location loc_vip_nodo01 vip_nodo01 100: NODO01 location loc_vip_nodo02 vip_nodo02 100: NODO02 property cib-bootstrap-options: dc-version=1.1.15-5.el6-e174ec8 cluster-infrastructure=cman start-failure-is-fatal=false stonith-enabled=false no-quorum-policy=ignore have-watchdog=false rsc_defaults rsc_defaults-options: migration-threshold=0 failure-timeout=2s resource-stickiness=50
9) Modgearman
Passaremos agora a configurar o módulo gearman para o core do OpMon, chamado de modgearman. Este é composto por dois itens, um chamado de worker e outro chamado de neb. O neb sobre sempre junto ao processo do OpMon, enquanto o worker deve rodar nos dois nodos pois é ele quem executa as checagens. Em outras palavras, o neb escala as checagens e o worker as executa. Como o processo gearmand sempre roda junto ao processo do OpMon, precisamos configurar o neb para que escale as checagens para o gearmand local, onde todos os workers estão conectados. Para isso, basta conferir os arquivos /etc/mod_gearman/module.conf e /etc/mod_gearman/worker.conf e em ambos deve estar declarado uma linha identica a esta:
server=127.0.0.1:4730
Este processo deve ser executado em ambos os nodos.
Feito este procedimento agora precisamos inserir o endereço IP Virtual do NODO01 em nossa configuração de job servers. Acessando agora a interface do OpMon através do NODO01 clique em “Ferramentas”, logo após em “Configurações“, localize a opção “Main Config“ e então “Job Servers”, veja:

Agora nos resta reiniciar alguns processos para que subam com as novas configurações de Job Servers, este processo deve ser executado nos dois nodos:
[root@NODO01 ~]# services gearman-utils restart [root@NODO01 ~]# service mod-gearman-worker restart
[root@NODO02 ~]# services gearman-utils restart [root@NODO02 ~]# service mod-gearman-worker restart
10) Configurando o clean-incrementals
O processo de clean-incrementals limpa os arquivos incrementais do MariaDB que não são mais necessários. Antes de proceder com esta configuração precisamos assegurar que as bases de dados dos dois nodos estão 100% sincronizadas senão corremos o risco de perder dados. Em ambos os nodos logue no mysql e execute:
[root@NODO01]#mysql -p -A
...
MariaDB [(none)]> show slave statusG
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.19.0.2
Master_User: root
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: incremental.000005
Read_Master_Log_Pos: 348
Relay_Log_File: mysqld-relay-bin.000015
Relay_Log_Pos: 487
Relay_Master_Log_File: incremental.000005
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 348
Relay_Log_Space: 487
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Se os itens _Slave_IO_Running_ e Slave_SQL_Running estiverem como Yes, e Seconds_Behind_Master como ZERO, significa que a base está plenamente sincronizada, caso o Seconds_Behind_Master seja maior que ZERO, espere até o sincronismo finalizar para seguir os próximos passos.
Assim que o sincronismo estiver OK, no NODO01 editar o arquivo /usr/local/opmon/utils/clean-incrementals.pl e colocar o ip do NODO02 na variável:
$slave_address = "192.168.2.2";
Editar o mesmo arquivo, agora no NODO02 e colocar o IP do NODO01 conforme abaixo:
$slave_address = "192.168.2.1";
Agora, com a configuração feita, retornamos ao NODO01 e executamos:
[root@NODO01 ~]# /usr/local/opmon/utils/clean-incrementals.pl
Após a finalização do comando acima, faremos o mesmo processo porém agora no NODO02:
[root@NODO02 ~]# /usr/local/opmon/utils/clean-incrementals.pl
Agora só precisamos habilitar o agendamento da limpeza dos incrementais. No NODO01 editamos o arquivo /etc/cron.d/clean-incrementals e descomentamos a linha que faz referência ao clean-incrementals:
0 23 * * * root /usr/local/opmon/utils/clean-incrementals.pl >/dev/null 2>/dev/null
E reiniciamos o processo da crond. Devemos agora ir ao NODO02 e executar o mesmo procedimento editando o arquivo da crond e reiniciando o processo.
11) Fornecendo acesso ao Livestatus somente aos IPs do Cluster
Por questões de segurança dos dados, é importante que no arquivo de configuração do livestatus sejam listados somente o IP do OpMon e do cluster (IPs físicos e não virtuais). Para isso basta editar o seguinte arquivo de configuração /etc/xinetd.d/livestatus e incluir o(s) IP(s) do cluster, conforme o exemplo abaixo ilustrado:
DICA: caso esta linha esteja comentada, o livestatus aceitará conexão de qualquer endereço, e isso não será problema para o funcionamento do cluster.
only_from = 127.0.0.1 IP_FÍSICO_1 IP_FÍSICO_2
Checklist de validação do cluster
- Colocar a nova licença no nodo1 (suportando todos IPs de ambos nodos) e validar que a mesma foi sincronizada com o nodo2.
- Reiniciar o httpd em ambos nodos.
- Acessar via IP físico e virtual do NODO01 no browser.
- Acessar via IP físico e virtual do NODO02 no browser.
- Parar os recursos do cluster em um dos nodos e validar que os mesmos foram movidos para o outro nodo, realizar o teste em ambos os lados do cluster.
[root@NODO02 ~]# pcs cluster stop NODO02
[root@NODO01 ~]# crm_mon